


When consumers describe time in their own words, it can get messy—“probably 6 months ago,” “just now,” or even “a couple months back.” For data-driven businesses, this creates a challenge: how do you turn free-form, human language into structured, actionable insights?
Recently, a Fairing customer wanted to categorize over 100,000 responses to their open-ended question “When did you first hear about us?” to one of six categories. This question is important for figuring out time-lag and informs other measurement analyses. For more on its value, view our support center.
To do this promptly, we combined natural language processing (NLP) with smart automation, transforming thousands of messy, time-related responses into clean, standardized data. NLP, which combines linguistics and machine learning, is like having thousands of translators working continuously, turning messy human responses ('uhh maybe last month?') into clean, structured data that businesses can use at scale.
Here’s how we did it—and what we learned:
Cleaning Up
This cleanup process is important because messy data leads to messy insights. By standardizing and simplifying the responses, we created a solid foundation for further analysis. Here are the steps we took:
Step 1: Renaming Typos and Abbreviations
One of the first challenges was handling typos and shorthand. For example:
- Typos: “lasst mnth” should be “last month.”
- Abbreviations: People often write “yrs” instead of “years” or “mnths” instead of “months.”
To fix this, we used tools to correct misspellings and expand abbreviations. For example:
- “3 yrs ago” → “3 years ago”
- “a few mnths back” → “a few months back”
Step 2: Standardizing Time-Related Phrases
We created rules to translate these natural phrases into a consistent format, simplifying the process of grouping similar responses later. For example:
- “Just now” means “today”
- “A couple of days ago” means “in the last few days”
Step 3: Removing Unnecessary Words
Responses included irrelevant phrases like “I think,” “maybe,” or “just.” These words don’t add much meaning and can complicate data analysis. We removed these so that only the important parts of the response remained. For example:
- Original: “I think I heard about this a couple of days ago.”
- Cleaned: “a couple of days ago”
Step 4: Putting It All Together
To streamline the process, we combined all steps into one automated workflow:
- Convert everything to lowercase for consistency.
- Expand abbreviations like “yrs” into full words.
- Standardize phrases like “a few days ago” into uniform terms.
- Remove filler words like “just” or “maybe.”
After processing, each response was clean, standardized, and ready for categorization.
Categorization
Step 1: Teaching the Computer to Recognize Time Expressions
First, we designed a system to interpret time-related phrases. The goal was to recognize patterns people use to describe time, whether specific like ‘3 months ago’ or general like ‘a while back.’
Step 2: Using NLP for Complex Cases
Not all responses were straightforward. Phrases like “last year” don’t specify the time frame. We used a special NLP tool called a ‘sentence embedding’ model to compare the meaning of a response to our predefined categories and find the best match.
For instance:
- The NLP analyzes the phrase “last year” and compares it to categories like “over a year ago” or “in the last few days.”
- It selects the category that best matches the response’s meaning.
Step 3: Handling Unclear Responses
If the current model couldn’t confidently match a response to our categories, it labeled it as ‘Uncategorized’. This ensures we don’t force-fit data.
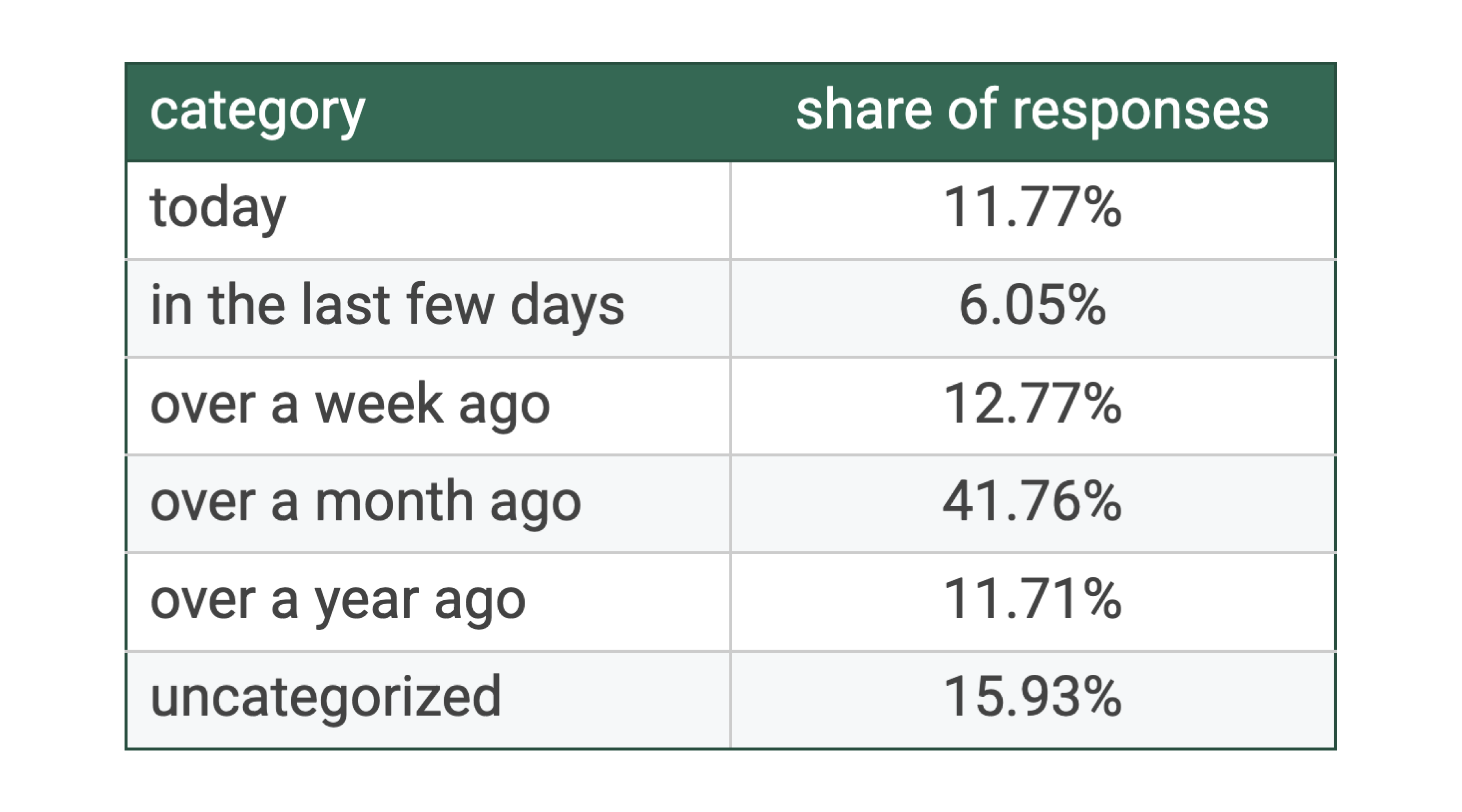
The Results
After processing all responses, each one was paired with a clear category. For example:
• “3 days ago” → In the last few days
• “Last year” → Over a year ago
• “I’m obsessed!!” → Uncategorized
